














































































- Home

- Blog
- Technical SEO
- Noindex Nofollow and Disallow: Search Crawler Directives
Noindex Nofollow and Disallow: Search Crawler Directives
Are you using NoIndex, NoFollow, and Disallow correctly? Not using them the right way can cost your web pages organic rankings. Learn all about them here.
There are three directives (commands) that you can use to dictate how search engines discover, store, and serve information from your site as search results:
- NoIndex: Don’t add my page to the search results.
- NoFollow: Don’t look at the links on this page.
- Disallow: Don’t look at this page at all.
These directives allow you to control which of your site pages can be crawled by search engines and appear in search.
What does No Index mean?
The noindex directive tells search crawlers, like googlebot, not to include a webpage in its search results.

How Do You Mark A Page NoIndex?
There are two ways to issue a noindex directive:
- Add a noindex meta tag to the page’s HTML code
- Return a noindex header in the HTTP request
By using the “no index” meta tag for a page, or as an HTTP response header, you are essentially hiding the page from search.
The noindex directive can also be used to block only specific search engines. For example, you could block Google from indexing a page but still allow Bing:
Example: Blocking Most Search Engines*
<meta name=”robots” content=”noindex”>
Example: Blocking Only Google
<meta name=”googlebot” content=”noindex”>
Please note: As of September 2019, Google no longer respects noindex directives in the robots.txt file. Noindex now MUST be issued via HTML meta tag or HTTP response header. For more advanced users, disallow still works for now, although not for all use cases.
What is the difference between noindex and nofollow?
It’s a difference between storing content, and discovering content:
noindex is applied at the page-level and tells a search engine crawler not to index and serve a page in the search results.
nofollow is applied at the page or link level and tells a search engine crawler not to follow (discover) the links.
Essentially the noindex tag removes a page from the search index, and a nofollow attribute removes a link from the search engine’s link graph.
NoFollow As a Page Attribute
Using nofollow at a page level means that crawlers will not follow any of the links on that page to discover additional content, and the crawlers will not use the links as ranking signals for the target sites.
<meta name=”robots” content=”nofollow”>
NoFollow as a Link Attribute
Using nofollow at a link level prevents crawlers from exploring ad specific link, and prevents that link from being used as a ranking signal.
The nofollow directive is applied at a link level using a rel attribute within the a href tag:
<a href=”https://domain.com” rel=”nofollow”>
For Google specifically, using the nofollow link attribute will prevent your site from passing PageRank to the destination URLs.
Why Should You Mark a Page as NoFollow?
For the majority of use cases, you should not mark an entire page as nofollow – marking individual links as nofollow will suffice.
You would mark an entire page as nofollow if you did not want Google to view the links on the page, or if you thought the links on the page could hurt your site.
In most cases blanket page-level nofollow directives are used when you do not have control over the content being posted to a page (ex: user generated content can be posted to the page).
Some high-end publishers have also been blanket applying the nofollow directive to their pages to dissuade their writers from placing sponsored links within their content.
How Do I Use NoIndex Pages?
Mark pages as noindex that are unlikely to provide value to users and should not show up as search results. For example, pages that exist for pagination are unlikely to have the same content displayed on them over time.
Domain.com/category/resultspage=2 is unlikely to show a user better results than domain.com/category/resultspage=1 and the two pages would only compete with each other in search. It’s best to noindex pages whose only purpose is pagination.
Here are types of pages you should consider noindexing:
- Pages used for pagination
- Internal search pages
- Ad-Optimized Landing pages
- Ex: Only displays a pitch and sign up form, no main nav
- Ex: Duplicate variations of the same content, only used for ads
- Archived author pages
- Pages in checkout flows
- Confirmation Pages
- Ex: Thank you pages
- Ex: Order complete pages
- Ex: Success! Pages
- Some plugin-generated pages that are not relevant to your site (ex: if you use a commerce plugin but don’t use their regular product pages)
- Admin pages and admin login pages
Marking a Page Noindex and Nofollow
A page marked both noindex and nofollow will block a crawler from indexing that page, and block a crawler from exploring the links on the page.
Essentially, the image below demonstrates what a search engine will see on a webpage depending on how you’ve used noindex and nofollow directives:

Marking an Already Indexed Page as NoIndex
If a search engine has already indexed a page, and you mark it as noindex, then next time the page is crawled it will be removed from the search results.
For this method of removing a page from the index to work, you must not be blocking (disallowing) the crawler with your robots.txt file.
If you are telling a crawler not to read the page, it will never see the noindex marker, and the page will stay indexed although its content will not be refreshed.
How do I stop search engines from indexing my site?
If you want to remove a page from the search index, after it has already been indexed, you can complete the following steps:
- Apply the noindex directiveAdd the noindex attribute to the meta tag or HTTP response header
- Request the search engine crawl the pageFor Google you can do this in search console, request that Google re-index the page. This will trigger Googlebot crawling the page, where Googlebot will discover the noindex directive.You will need to do this for each search engine that you want to remove the page.
- Confirm the page has been removed from searchOnce you’ve requested the crawler revisit your webpage, give it some time, and then confirm that your page has been removed from the search results. You can do this by going to any search engine and entering site colon target url, like in the image below.
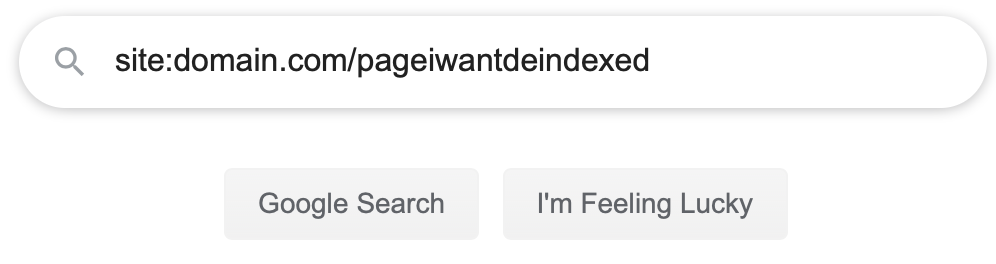
If your search returns no results, then your page has been removed from that search index. - If the page has not been removedCheck that you do not have a “disallow” directive in your robots.txt file. Google and other search engines cannot read the noindex directive if they are not allowed to crawl the page.If you do, remove the disallow directive for the target page, and then request crawling again.
- Set a disallow directive for the target page in your robots.txt fileDisallow: /page$
You’ll need to put the dollar sign on the end of the URL in your robots.txt file or you may accidentally disallow any pages under that page, as well as any pages that begin with the same string.Ex: Disallow: /sweater will also disallow /sweater-weather and /sweater/green, but Disallow: /sweater$ will only disallow the exact page /sweater.
How to Remove a Page from Google Search
If the page you want removed from search is on a site that you own or manage, most sites can use the Webmaster URL Removal Tool.
The Webmaster URL removal tool only removes content from search for about 90 days, if you want a more permanent solution you’ll need to use a noindex directive, disallow crawling from your robots.txt, or remove the page from your site. Google provides additional instructions for permanent URL removal here.
If you’re trying to have a page removed from search for a site that you do not own, you can request Google removes the page from search if it meets the following criteria:
- Displays personal information like your credit card or social security number
- The page is part of a malware or phishing scheme
- The page violates the law
- The page violates a copyright
If the page does not meet one of the criteria above, you can contact an SEO firm or PR company for help with online reputation management.
Should you noindex category pages?
It is usually not recommended to noindex category pages, unless you are an enterprise-level organization spinning up category pages programmatically based on user-generated searches or tags and the duplicate content is getting unwieldy.
For the most part if you are tagging your content intelligently, in a way that helps users better navigate your site and find what they need, then you’ll be okay.
In fact, category pages can be goldmines for SEO as they typically show a depth of content under the category topics.
Take a look at this analysis we did in December, 2018 to quantify the value of category pages for a handful of online publications.
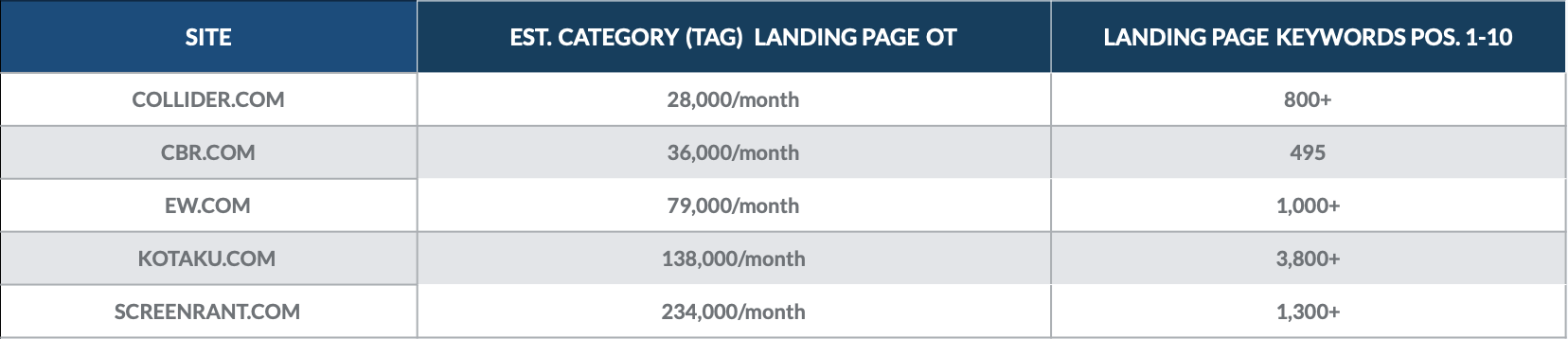
We found that category landing pages ranked for hundreds of page 1 keywords, and brought in thousands of organic visitors each month.
The most valuable category pages for each site often brought in thousands of organic visitors each.
Take a look at EW.com below, we measured the traffic to each page (represented by the size of the circle) and the value of the traffic to each page (represented by the color of the circle).
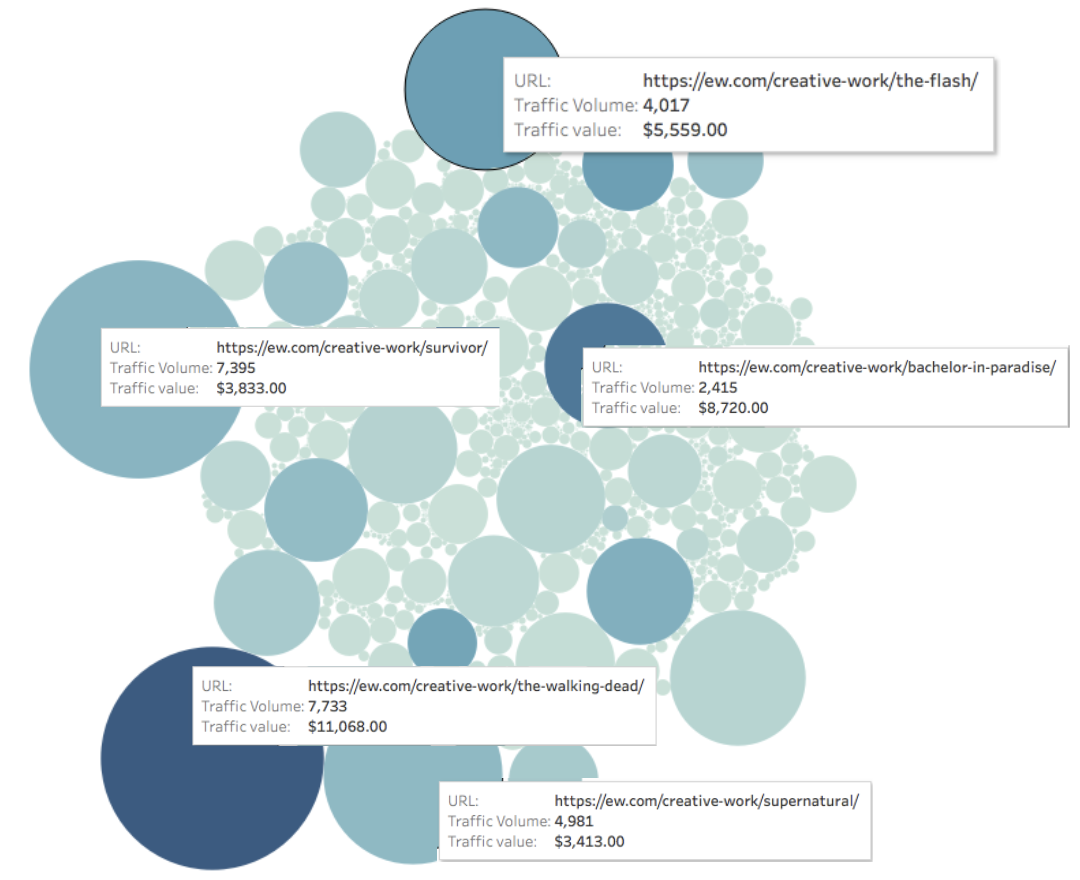
Monthly Organic Value of Page = Depth of Color
Now imagine the same charts, but for product-based sites where visitors are likely to make active purchases.
That being said, if your categories similar enough to cause user confusion or compete with each other in search then you may need to make a change:
- If you are setting the categories yourself, then we would recommend migrating content from one category to the other and reducing the total number of categories you have overall.
- If you are allowing users to spin up categories, then you may want to noindex the user generated category pages, at least until the new categories have undergone a review process.
How do I stop Google from indexing subdomains?
There are a few options to stop Google from indexing subdomains:
- You can add a password using an .htpasswd file
- You can disallow crawlers with a robots.txt file
- You can add a noindex directive to every page in the subdomain
- You can 404 all of the subdomain pages
Adding a Password to Block Indexing
If your subdomains are for development purposes, then adding an .htpasswd file to the root directory of your subdomain is the perfect option. The login wall will prevent crawlers for indexing content on the subdomain, and it will prevent unauthorized user access.
Example use cases:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Using robots.txt to Block Indexing
If your subdomains serve other purposes, then you can add a robots.txt file to the root directory of your subdomain. It should then be accessible as follows:
https://subdomain.domain.com/robots.txt
You will need to add a robots.txt file to each subdomain that you are trying to block from search. Example:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
In each case the robots.txt file should disallow crawlers, to block most crawlers with a single command, use the following code:
User-agent: *
Disallow: /
The star * after user-agent: is called a wildcard, it will match any sequence of characters. Using a wildcard will send the following disallow directive to all user agents regardless of their name, from googlebot to yandex.
The backslash tells the crawler that all pages off of the subdomain are included in the disallow directive.
How to Selectively Block Indexing of Subdomain Pages
If you would like some pages from a subdomain to show up in search, but not others, you have two options:
- Use page-level noindex directives
- Use folder or directory-level disallow directives
Page level noindex directives will be more cumbersome to implement, as the directive needs to be added to the HTML or Header of every page. However, noindex directives will stop Google from indexing a subdomain whether the subdomain has already been indexed or not.
Directory-level disallow directives are easier to implement, but will only work if the subdomain pages are not in the search index already. Simply update the subdomain’s robots.txt file to disallow crawling of the applicable directories or subfolders.
How Do I Know if My Pages are NoIndexed?
Accidentally adding a no index directive pages on your site can have drastic consequences for your search rankings and search visibility.
If you find a page isn’t seeing any organic traffic despite good content and backlinks, first spot check that you haven’t accidentally disallowed crawlers from your robots.txt file. If that doesn’t solve your issue, you’ll need to check the individual pages for noindex directives.
Checking for NoIndex on WordPress Pages
WordPress makes it easy to add or remove this tag on your pages. The first step in checking for nofollow on your pages is by simply toggling the Search Engine Visibility setting within the “Reading” tab of the “Settings” menu.
This will likely solve the problem, however this setting works as a ‘suggestion’ rather than a rule, and some of your content may end up being indexed anyway.
In order to ensure absolute privacy for your files and content, you will have to take one final step either password protecting your site using either cPanel management tools, if available, or through a simple plugin.
Likewise, removing this tag from your content can be done by removing the password protection and unchecking the visibility setting.
Checking for NoIndex on Squarespace
Squarespace pages are also easily NoIndexed using the platform’s Code Injection capability. Like WordPress, Squarespace can easily be blocked from routine searches using password protection, however the platform also advises against taking this step to protect the integrity of your content.
By adding the NoIndex line of code within each page you want to hide from internet search engines and to each subpage below it, you can ensure the safety of secured content that should be barred from public access. Like other platforms, removing this tag is also fairly straightforward: simply using the Code Injection feature to take the code back out is all you will need to do.
Squarespace is unique in that its competitors offer this option primarily as a part of the suite of settings in page management tools. Squarespace departs here, allowing for personal manipulation of the code. This is interesting because you are able to see the change you are making to your page’s content, unlike the others in this space.
Checking for NoIndex on Wix
Wix also allows for a simple and fast fix for NoIndexing issues. In the “Menus & Pages” settings, you can simply deactivate the option to ‘show this page in search results’ if you want to NoIndex a single page within your site.
As with its competitors, Wix also suggests password protecting your pages or entire site for extra privacy. However, Wix departs from the others in that the support team does not prescribe parallel action on both fronts in order to secure content from the crawler. Wix makes a particular note about the difference between hiding a page from your menu and hiding it from search criteria.
This is particularly useful advice for less experienced website builders who may not initially understand the difference considering that removal from your site menu makes the page unreachable from the site, but not from a prudent Google search term.






