- Resources

-
-
-
-
- Free consultation
![phone number]() (929) 377 1035
(929) 377 1035
-
-
- About
-
-
- Hi. We’re LinkGraph.
-
-
-
-
-
- Free consultation
![phone number]() (929) 377 1035
(929) 377 1035
-
-










































































- SEO Services
-
-
Managed SEO Banner
-
Link Building Service
HARO Link Building
Digital PR
Publisher Outreach
Guest Posting
Partnership-led SEO
GMB Management
Local SEO Services
-
SEO Auditing
Website Migrations
Page Speed Optimization
Technical SEO
Content Strategy
Copywriting
Keyword Research
On-Page SEO Services
Blog Writing Services
-
Google Ads
Facebook Ads
PPC
Amazon Ads
Our Blueprint
SEO Advisory
Brand Defense
Conversion Rate Optimization
Youtube SEO
See All Services
-
-
-
- Free consultation
![phone number]() (929) 377 1035
(929) 377 1035
-
-
- SEO Software
-
-
Bulk DA Checker
SEO Content Optimizer
SEO Content Assistant
Rank Tracking
Keyword Research
Backlink Analysis
-
-
-
Phone Number
Free consultation![phone number]() (929) 377 1035
(929) 377 1035
-
-
- For Agencies
-
-
White Label Link Building
White Label SEO
White Label SEO Software
White Label PPC Services
-
-
-
Phone Number
Free consultation![phone number]() (929) 377 1035
(929) 377 1035
-
-
- Industry Solutions
-
-
SEO for B2B Companies
SEO for Ecommerce Brands
SEO for SaaS Companies
SEO for Healthcare Companies
SEO for Government
SEO for Enterprise Companies
SEO for Law Firms
SEO for Dentists
-
SEO for Doctors
SEO for Startups
National SEO
International SEO
Small Business SEO
Local SEO
Big Commerce SEO
Shopify SEO
-
-
-
Phone Number
Free consultation![phone number]() (929) 377 1035
(929) 377 1035
-
-
- Resources
-
-
-
-
- Free consultation
![phone number]() (929) 377 1035
(929) 377 1035
-
-
- About
-
-
- Hi. We’re LinkGraph.
-
-
-
-
-
- Free consultation
![phone number]() (929) 377 1035
(929) 377 1035
-
-


Award Winning SEO Services Designed
For Agencies And Established Brands
Powering 8178+ marketing agencies around the globe.

 For Agencies
For Agencies
 For Brands
For Brands


Agency pricing comes in different levels to cater to varying needs. Our $249 package provides essential services, while the $499 and $999 packages offer more extensive strategies, including advanced techniques to improve your clients’ rankings.

Increase your Domain Authority, content quality, and website performance with our SEO packages designed for brands. We offer SEO packages at various pricing levels, from basic essential services to more extensive strategies and advanced techniques.
800+ organizations trust LinkGraph to drive growth











“We have white-labeled several SEO campaigns with LinkGraph. I have been thoroughly impressed by their expertise, professionalism, and attention to detail. They debrief after meetings, explain strategy, and check in without being prompted. They have even helped close new accounts. LinkGraph sincerely goes above and beyond.”


Our Core SEO Ranking Factors
We increase website authority through high-quality backlinks from industry-specific websites. With more high-quality backlinks, search engines will see your website as more trustworthy, leading to better organic rankings across every page of your website.
We create high-quality, SEO-optimized content that will connect you to your target audience. We focus on the content that will generate the highest profitability for your agency or brand. With more high-quality content on your website, Google will see your clients or your brand as industry experts.
Our technical SEO experts will optimize your website so search engines find, crawl, and index your pages. Plus, optimized meta data helps search engines better understand what your content is about and what keywords to rank it for. We focus on relevance and clickability to increase click-through-rates and user engagements.
The UX Signals of your content influences your organic rankings in search engines. We make sure your pages are fast-loading and responsive, optimizing them to meet Google’s performance standards. With higher Pagespeed Insights scores and passing Core Web Vitals, we help improve the visibility of your entire domain.
Factor-Based SEO for Agencies and Established Brands.
LinkGraph uses its trademarked Factor-Based SEO blueprint to deliver incredible organic traffic results for clients. Our holistic SEO approach focuses on improving websites according to Google’s core ranking factors: Authority + Content + Technicals + UX Signals.



Our SEO agency works to elevate the quality-signals of your web pages in all of these core areas. Through our data-driven SEO service and proprietary software, we help Google see your content as more relevant, more valuable, and more authoritative than your competitors.

Higher Value For Your Clients.
More Profit For Your Agency.
Successful agencies and brands work with LinkGraph to
elevate their growth and profitability.

- Blog posts (AI generated)
- PR Syndication
- Whitelabeled SA
- Otto - AI Content Optimization (includes Titles, Metas, Schema)
- Local SEO Geogrids / Heatmaps
- Client reporting dashboard for realtime order tracking and reporting
- Site Audits and Reports

- Blog posts (AI generated)
- GMB optimization
- Cloud Stacks
- CTR
- Whitelabeled SA
- Otto - AI Content Optimization (includes Titles, Metas, Schema)
- PR Syndication
- Reporting Dashboard

- Blog posts (AI generated)
- GMB optimization + posts
- Cloud Stacks
- CTR
- Whitelabeled SA
- Otto - AI Content Optimization (includes Titles, Metas, Schema)
- Link Building
- PR Syndication
- On-page audits
- Technical audits
- Reporting Dashboard

- Blog posts (AI generated)
- GMB optimization + posts
- Cloud Stacks
- Citation Building
- CTR
- Whitelabeled SA
- Otto - AI Content Optimization (includes Titles, Metas, Schema)
- Link Building
- Tier 2 Link Building
- PR Syndication
- Keyword Research
- On-page audits
- Technical audits
- Reporting Dashboard


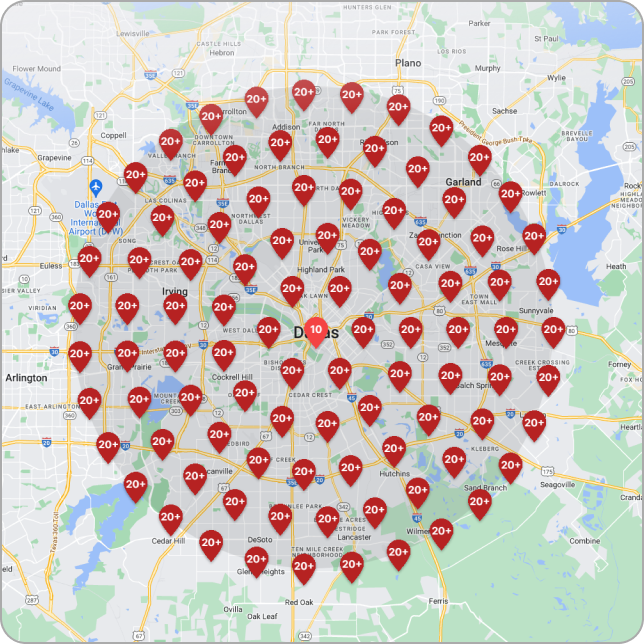
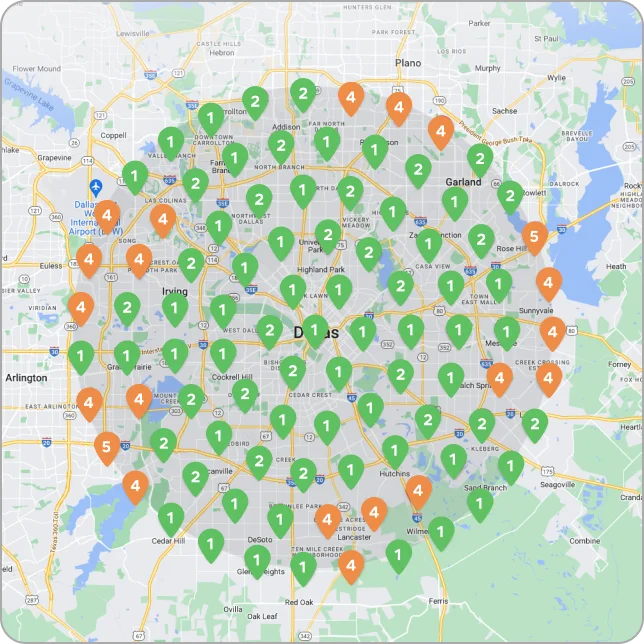
Expert Local SEO Strategies and Heatmap Insights
Transform your clients’ local online presence from mediocre to exceptional through our cutting-edge Heatmap technology. Enhance the visibility and presence of local businesses through strategic location-based optimization, increased traffic, and converting online searches into real-world customers for your clients.
Are you ready to seriously scale?
Choose only the products you need right now from our comprehensive menu. Whether you need a quick authority boost or a comprehensive growth package, we got you covered.
See why the world's best companies choose LinkGraph to drive leads, traffic and revenue.
“They are dedicated to our success and are a thoughtful sounding board when we run ideas by them – sometimes on ideas and projects that are tangential to our main SEO project with them. Also, I love that they allow for shorter-term contracts compared to the usual 1-year contract with other SEO companies. Lastly, they deliver on their promises.”


Get Started

Work with our Award-Winning SEO Strategists
The LinkGraph team consists of SEO experts, industry-leading web developers, and editorial experts. With our talent and groundbreaking software suite, it’s easy to guarantee results from our managed SEO campaigns.

Ted Hunting, Senior VP of Marketing
“Their creative, strategic approach, and the intelligence of their team members is beyond what other companies in the space can provide. Trust and rely on their expertise, because they know what they’re doing.”

Owner, Digital Agency
Clutch Review 2022
“Within the first few months of the campaign being live, we were the number one result for Orlando SEO companies. Since then, they’ve delivered those kinds of results for a number of our client companies as well.”

Senior Marketing Manager, Financial Services Industry
Clutch Review 2022
“From our initial consultation and throughout each month, LinkGraph has delivered results for us. The workflow has been seamless. We’re seeing more results and moving forward with more deliverables than we could with just our team alone.”

Chief Information Officer, Ecommerce retailer
Clutch Review 2022
“LinkGraph provided education, guidance, expert level assistance, and state of the art tools to allow us to identify and repair several issues with our site. We have become a force to be reckoned with in our market thanks to their team.”

The LinkGraph Guarantee
With every managed SEO campaign, we guarantee measurable results in keyword rankings, organic traffic, or overall search visibility.

Trusted by the world's fastest-growing marketing agencies
LinkGraph has driven growth for hundreds of brands in every industry. Learn more about our strategic approach in our case studies.


“Their creative, strategic approach, and the intelligence of their team members is beyond what other companies in the space can provide. Trust and rely on their expertise, because they know what they’re doing.”
Keep Learning with Us
LinkGraph is committed to driving innovation in the SEO space by producing data science research, free eBooks, thought leadership pieces, webinars and more.
-
 Webinars
Webinars -
 EBooks
EBooks -
 Blog posts
Blog posts -
Videos
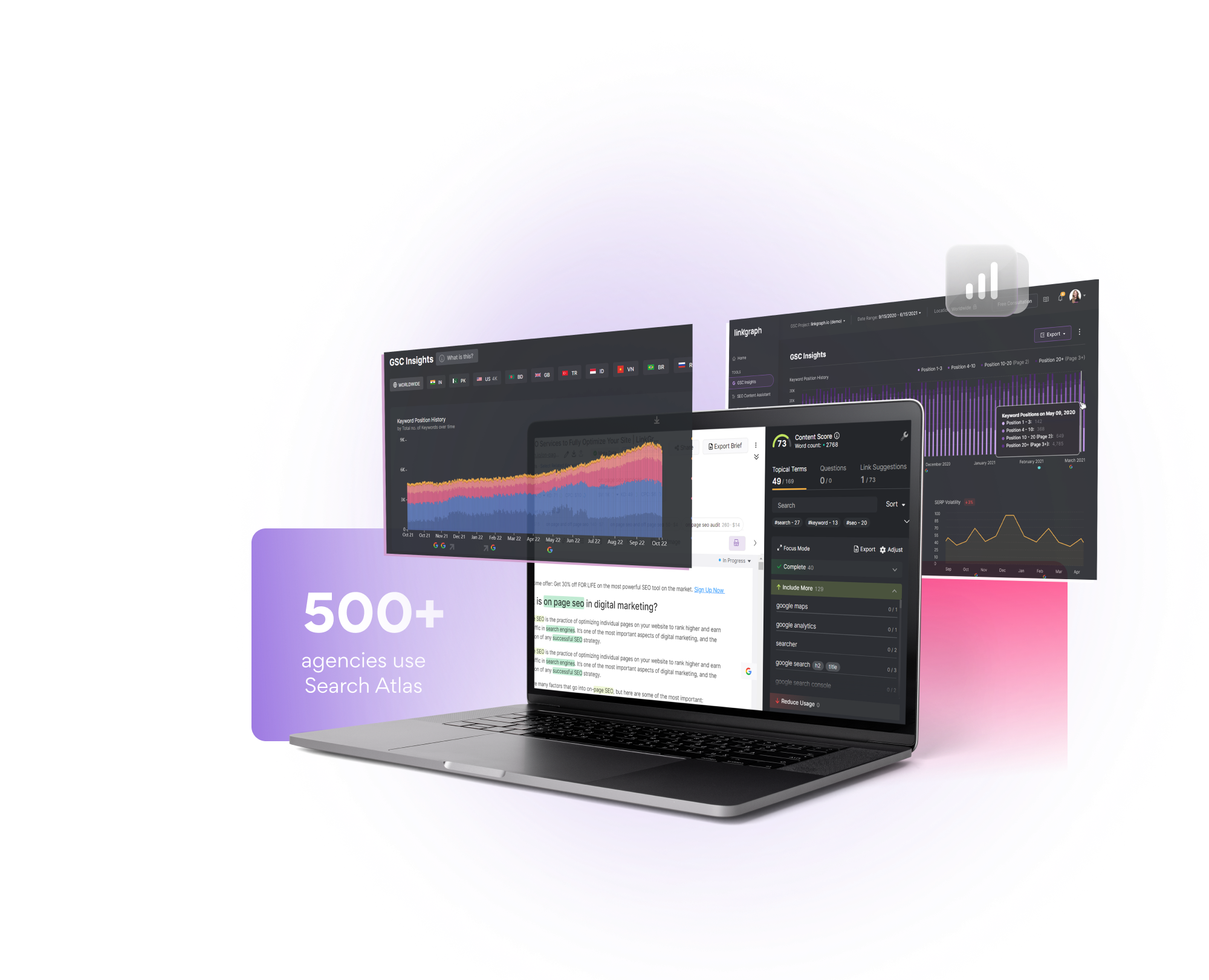
Take Your SEO To The Moon With Our Groundbreaking SEO Software Suite

Generate thousands of organic clicks with LinkGraph’s enterprise SEO software platform. Reach your growth goals and scale your revenue faster with SEO automation tools.